
NVIDIA 擁有數(shù)十種 GPU,可用于處理不同大小的 ML 模型。但要了解這些不同顯卡的性能和成本,更不用說記住它們的名稱,卻是一項(xiàng)挑戰(zhàn)。每個 GPU 的名稱(一個字母數(shù)字標(biāo)識符)都傳達(dá)了有關(guān)其架構(gòu)和規(guī)格的信息。
每個人都想要功能強(qiáng)大、經(jīng)濟(jì)高效的硬件來運(yùn)行生成式 AI 工作負(fù)載和 ML 模型推理。但選擇數(shù)據(jù)中心 GPU 并不像走進(jìn) Apple 商店挑選一臺新筆記本電腦那么簡單,因?yàn)槟抢镏挥猩贁?shù)幾個選項(xiàng)和明確的升級路徑。這更像是買車,您的預(yù)算和用例會指導(dǎo)您在具有不同功能、價格和可用性的一系列型號和車型年份中做出決定。
本文首先會引導(dǎo)您解讀 NVIDIA 數(shù)據(jù)中心 GPU 的命名方案,以識別顯卡的架構(gòu)和層級。然后,本文將提供清晰直接地比較不同 GPU 的方法,以及用于模型訓(xùn)練、微調(diào)和服務(wù)的幾款流行顯卡的關(guān)鍵規(guī)格表。
數(shù)據(jù)中心 GPU 可以有相當(dāng)神秘的名稱:K80、T4、A100、L40。但這些不僅僅是字母和數(shù)字的隨機(jī)集合。它們編碼了有關(guān) GPU 規(guī)格和性能的重要信息。
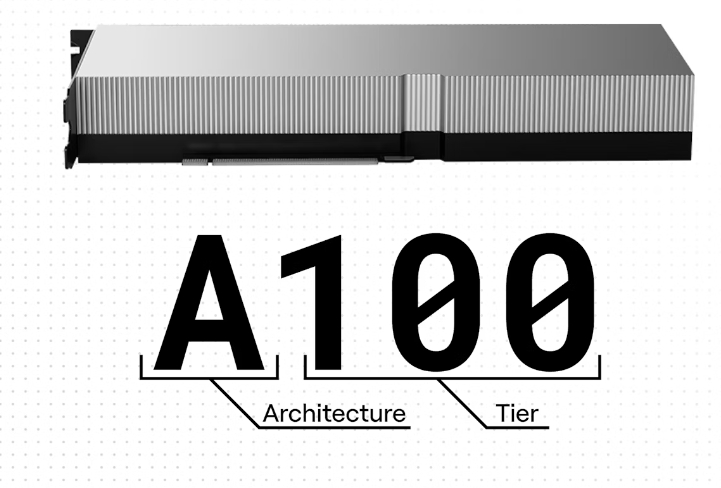
一、字母:顯卡架構(gòu)
GPU 名稱中的字母代表該 GPU 的架構(gòu)。每隔幾年,NVIDIA 就會為消費(fèi)級和數(shù)據(jù)中心產(chǎn)品的 GPU 發(fā)布一種新的微架構(gòu)。新的微架構(gòu)通過更新的指令集提高了性能和能效,并且通常利用更小的工藝節(jié)點(diǎn)將更多的晶體管封裝到每個芯片上。每個新的微架構(gòu)都意味著更快、更優(yōu)化的 GPU。
在 GPU 的名稱中,字母是架構(gòu)名稱的首字母。例如,A 代表 Ampere,L 代表 Lovelace。NVIDIA GPU 架構(gòu)以著名科學(xué)家的名字命名。
的時間線")
二、卡層數(shù)
對于每種架構(gòu),NVIDIA 都會制造幾種具有不同價格、性能和功耗目標(biāo)的 GPU。數(shù)字越大,GPU 的功能越強(qiáng)大,價格也越昂貴。
不同級別的 GPU 針對不同的計算工作負(fù)載進(jìn)行了優(yōu)化。最近幾代的 GPU 級別包括:
4:一代中最小的 GPU,4 層卡能耗低,最適合經(jīng)濟(jì)高效地調(diào)用中等大小的模型。
10:針對AI推理優(yōu)化的中端GPU。
40:最適合虛擬工作站、圖形和渲染的高端 GPU。
100:這一代 GPU 中規(guī)模最大、價格最昂貴、性能最強(qiáng)。它擁有最高的核心數(shù)和最大 VRAM,專為大型模型推理以及新模型的訓(xùn)練和微調(diào)而設(shè)計。
三、示例比較
有了這兩個因素,我們可以使用 GPU 名稱中的字母和數(shù)字組合來推斷有關(guān)卡的一些事實(shí)。
例如:T4 和 L4 有什么區(qū)別?
L4 是 T4 的下一代替代品。L4 使用 Lovelace 架構(gòu),于 2023 年發(fā)布,而 T4 使用 Turing 架構(gòu),于 2018 年發(fā)布。這兩款顯卡屬于同一層級——它們使用的功率相似,設(shè)計用于相似的用例——但較新的 L4 擁有更強(qiáng)大的內(nèi)核和 24 GB 的 VRAM,而 T4 只有 16 GB。
例如:A10 和 A100 有什么區(qū)別?
A100 是 A10 的更大、更強(qiáng)大、更昂貴的版本。兩款顯卡具有相同的架構(gòu),但 A100 擁有更多內(nèi)核和 VRAM,功耗更高,因此它可以運(yùn)行更大的模型,并且運(yùn)行速度更快。
例如:如何比較 K80 和 T4?
任何兩張不同架構(gòu)和不同級別的顯卡之間的比較都很復(fù)雜。K80 采用已有十年歷史的 Kepler 架構(gòu),而 T4 采用更現(xiàn)代的 Turing 架構(gòu)。因此,對于許多 ML 任務(wù)而言,T4 每分鐘的運(yùn)行成本更低(因?yàn)楣母停瑫r由于其核心更強(qiáng)大,運(yùn)行速度也比 K80 快得多。











